[논문 리뷰] (SHIP) Improving Zero-Shot Generalization for CLIP with Synthesized Prompts
Improving Zero-Shot Generalization for CLIP with Synthesized Prompts - ICCV 2023
이번에는 Co-CoOp의 방식을 차용한 논문에 대해 리뷰하도록 하겠습니다.
https://arxiv.org/abs/2307.07397
Improving Zero-Shot Generalization for CLIP with Synthesized Prompts
With the growing interest in pretrained vision-language models like CLIP, recent research has focused on adapting these models to downstream tasks. Despite achieving promising results, most existing methods require labeled data for all classes, which may n
arxiv.org
지난 Co-CoOp이 궁금하시다면,,,
https://jiankim3293.tistory.com/26
[논문 리뷰] (Co-CoOp) Conditional Prompt Learning for Vision-Language Models
Conditional Prompt Learning for Vision-Language Modelshttps://arxiv.org/abs/2203.05557v2 Conditional Prompt Learning for Vision-Language ModelsWith the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways
jiankim3293.tistory.com
Introduction
최근 몇년간 language-supervised vision pretrained model이 많은 주목을 받았다.
이러한 모델은 image와 자연어 간의 연결을 통해 zero-shot의 능력과 놀라운 transfer 능력을 보여준다.
prtrain된 CLIP을 downstream task에 맞게 fine-tune하기 위해 주요 연구 라인은 learnable pormpt와 adaptors로 나뉠 수 있다.
Learnable prompt: 시간이 소요되는 hand craft prompt engineering의 문제점을 해소하기 위해 train시에 continous token embedding space에서 클래스에 구애받지 않는 prompt template을 자동으로 최적화 하는 것.
adaptor : CLIP-adaptor는 마지막 vision layer에 가벼운 MLP를 추가하고, output feature를 residual connection을 통해 원래의 zero-shot 특징과 혼합하는 것.
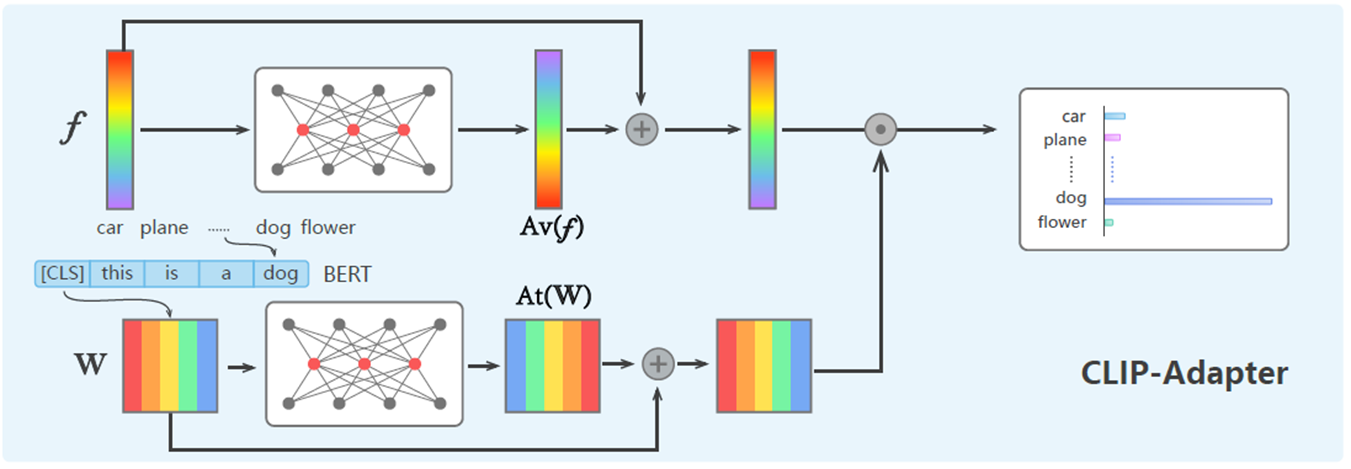

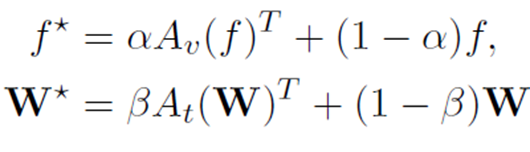
이러한 방법은 모든 클래스에 대해 사용할 수 있어야 하는데 실제 응용에서 비현실적일 수 있다.
새로운 종이나 새로운 개념과 같은 희귀 카테고리에 대한 데이터를 수집하는것이 어려워서 문제가 발생한다.
따라서, 이전 방법들의 뛰어난 데이터 효율성을 유지하면서, 사용가능한 데이터가 있는 카테고리와 사용가능한 데이터가 없는 카테고리 모두를 효과적으로 인식 할 수 있는 fine- tune 방법을 개발하고자 하는 것이다.
새로운 클래스를 해당 image 없이 어떻게 표현할 것인가가 목표이다.
Overview
이 논문은 클래스 이름만을 기반으로 데이터가 없는 카테고리의 특징을 합성할 수 있는 새로운 generative한 접근방법인 SyntHesIzed Prompts (SHIP)을 제안한다.
지난 Co-CoOp에서 Meta-net이라는 lightweight neural network 방식을 사용했었다.
이번 SHIP에서는 Meta-net의 역할을 VAE를 활용하여 수행한다.
VAE를 학습시키기 위해서 고정된 CLIP visual encoder를 활용하여 입력 image feature를 추출한다.
VAE를 이용하여 generator를 도입하고, 합성된 prompt와 해당 클래스 이름을 CLIP의 text encoder에 입력하여 image feature를 구성한다.
라벨이 있는 base class특징과 합성된 새로운 class 특징을 결합하고 CoOp과 같은 기존의 fine-tune방법을 사용한다.

VAE는 Encoder-Decoder 구조를 통해서 base class들을 기반으로 학습되며, latent -> original로 reconstruct 하도록 학습한다. recon. 하는동안 image instance feature의 semantic한 정보들을 추출하고, 이를 new에 적용하도록 사용한다.
즉 VAE를 이용해 semantic한 정보를 이용하겠다는 것이다.
r : Co-CoOp의 phi와 같음
r은 MLP 네트워크를 통해 얻는다
r값을 prompt embedding vector에 concat하여 사용한다.
VAE는 original feature를 latent space로 보냈다가 다시 original feature와 유사하게 복원할 수 있도록 학습된다.
이때 object는 Evidence-Lower Bound(ELBO)로써 generative model들의 근간이 되는 학습법을 사용한다.
ELBO는 recon.을 위해 사용되는 recon. loss와 latent space 내에서 regularization term으로 동작하는 KL-Divergence가 같이 존재한다. (latent space내의 distribution이 원하는 distribution이 될 수 있도록 normal distribution)

ELBO = reconstruction loss - (KL-divergence loss)
L(recon) : 원본이미지가 들어오면 generator가 출력하는 x^(image feature)가 x(input image feature)를 닮을 수 있게끔 하는 loss
L(KL): latent space내에서 noise를 넣는데 우리가 원하는 distribution이 되도록하는 regularization term
encoder는 특징 x를 latent z로 encoding하고, generator는 z와 클래스 이름 c를 기반으로 특징 z를 재구성 한다.

prompt 구성은 CoOp과 마찬가지로 global하게 사용되는 context embedding vector(p) 들을 나열하고, bias r을 모든 p에 추가하는 형태로 사용한다.
뒤에 text encoder는 CLIP text encoder로, 이를 활용해서 scratch보다 빠르게 훈련이 가능하며 text encoder의 sematic information을 활용할 수 있다.
generator를 design한 방법은 CLIP의 방법을 기반으로한다.
prompt 학습방법에서 특징을 직접 생성하는 대신 instance별로 prompt를 generate한다.
구체적으로, z가 주어지면 instance별로 prompt를 generate한다.


L: prompt의 길이
p(z): 생성된 prompt
p는 learnable prompt의 global fixed set
Inference

inference시에 normal distribution noise와 class 이름을 통해 new class에 대한 embedding을 만들어 낸다.
new class의 클래스 이름 c와 사전 분포에서 샘플링된 noise z가 주어지면 generator를 사용해서 해당 특징을 생성한다.
Noise를 N(0,1)에서 랜덤하게 하나 뽑고, 새롭게 보는 카테고리에서 하나를 generator에 넣어서,
만들어지는 output feature를 다시 CLIP text encoder에 넣어서 수행한다.
생성된 embedding은 text encoder를 지나 특정 feature가 되며 zero-shot에 사용된다.
이 과정을 각 new class에 대해 반복하여 새로운 합성 데이터셋을 생성한다.
라벨이 있는 기본 데이터셋과 결합하면 모든 클래스에 대해 완전한 데이터셋을 얻을 수 있다.
실험결과
zero-shot
Base- to - new generalization
각 데이터셋을 두개의 subset으로 분할한다. base class와 new class
각 클래스당 16개의 샘플로 base class에서 훈련을 수행하고, 모델을 base class와 new class에서 모두 평가했다.

Cross- dataset transfer learning
ImageNet으로 pretreain후 generate model을 사용하여 모든 클래스에 대한 특징을 생성하고 합성된 데이터로 CoOp을 fine-tune 한다.

Generalized zero-shot learning
모델은 각 클래스당 16개의 샘플대신 seen class의 전체 train set에서 train한다.

ablation & representation
VAE를 썼으니 GAN을 쓸 수 있지 않을까 해서 ablation
CLIP text feature를 활용했기 때문에 scratch로 훈련시 성능차이가 있는지 확인

latent space내에서 저자가 주장한 prompt가 어떤 단어를 의미하는지 실제 vocabrary word embedding과 cosine 유사도를 통해 어떤 단어인지 추론한 결과, 실제 image의 semantic한 정보를 가지고 있음을 확인함.
(저자들은 해당 결과가 CLIP이 byte pair encoding이라는 방법을 통해 단어보다 작은 단위로 CLIP을 학습하였기 때문에 cosine 유사도를 사용했을때 일관되지 않고 정확하지 않은 결과가 나올 수 있지만, latent space가 의미를 가지는 것을 보여주기 위해 사용하였음)

Conclusion
이 논문은 일부 클래스에 데이터가 없는 시나리오를 처리하기 위해 SHIP이라는 생성적 접근 방식을 제공한다.
클래스 이름만을 기반으로 데이터가 없는 카테고리의 특징을 합성하여 사용할 수 있다.
VAE를 이용하여 합성된 prompt와 해당 클래스 이름을 CLIP의 text encoder에 입력하여 visual feature를 reconstruct하는 generator를 도입한다.
새로운 클래스의 데이터 격차를 줄이기 위해 data-efficient generator를 train 시킴으로써 성능을 개선했다.