Learning to Prompt for Vision-Language Models - IJCV 2022
https://arxiv.org/abs/2109.01134
Learning to Prompt for Vision-Language Models
Large pre-trained vision-language models like CLIP have shown great potential in learning representations that are transferable across a wide range of downstream tasks. Different from the traditional representation learning that is based mostly on discreti
arxiv.org
지난 포스팅에서 CLIP 논문을 리뷰했었는데, 이번엔 CLIP을 사용하여 prompt 기법을 적용한 논문 리뷰를 진행하겠다.
CLIP에 대한 논문 리뷰를 보고싶다면 https://jiankim3293.tistory.com/3
[논문 리뷰] Learning Transferable Visual Models From Natural Language Supervision (CLIP)
고정된 형태의 데이터를 이용해 컴퓨터 비전 모델을 학습시키는 것은 모델의 일반화 성능(generality)과 다른 태스크에서의 사용 가능성(usability) 제한이미지와 이 이미지를 설명하는 조금 더 상세
jiankim3293.tistory.com
CLIP은 prompt engineering을 사용했다면, 이번에 리뷰할 논문은 prompt learning을 사용하고자 한다.
간단하게 CLIP을 다시 짚고 넘어가자면,
CLIP은 Image-text pair를 가지고 훈련된 모델이다.
CLIP은 한 번도 학습하지 않은 이미지에 대해서도 적절히 분류작업을 수행할 수 있는 능력을 가지고 있다.
(CLIP에 소개된 방법은 간단하게 a photo of a "는 고정된 prompt, {class}부분은 지속적으로 변경시켜 image-text cosine similarity를 통해 분류를 진행했다)
여러 class로 구성된 prompt를 가지고 모든 class probability를 구하고 softmax를 통해서 가장 높게 나오는 class prompt를 prediction value로 지정한다.
CLIP을 통해서 few-shot을 수행할때 다양한 prompt를 구성해서 수행 할 수 있다.
prompt engineering의 문제점은?

테스트 하는 데이터 셋마다 성능이 잘 나오는 prompt가 다양하게 존재한다는 것을 확인 할 수 있다.
1. Word tuning에 많은 시간 소요
- a 라는 단어를 추가만 해줘도 성능 향상하는것을 볼 수 있다.
2. prompt 구성시 많은 사전지식(task, language model) 요구
- 적절한 task와 관련된 context를 세밀하게 추가하고 혹은 문장구조 tuning시 성능향상을 위해서는 많은 사전지식이 필요하다.
저자는 이러한 hand-crafted prompt들은 잘 나오는 것을 찾는것에도 많은 focusing이 필요하고 ime consuming적인 work로 본다. 또한 prompt에 많은 tuning을 해줘도 여전히 downstream task에 최적화되었다고 단정짓기 어렵다.
따라서 prompt engineering이 아닌, Context Optimizaion (CoOP)을 이 논문에서는 목표로 하고자 한다.
prompt를 trainable한 word embedding으로 두어 few-shot performance를 높이는 것을 목표로한다.
{class}는 few-shot 수행시에 dataset에 있는 class들을 모두 가져와서 변경해가며 사용할 수 있도록 changeable token.
CoOP : downstream image recognition에서 CLIP과 같은 vision-language model 도입.
Word embedding
여기서 prompt를 어떻게 학습하는지 짚고 넘어가자면, word embedding을 사용한다.

word embedding은 일종의 look-up table{dictionary}로써 원래는 NLP분야에서 단어를 수치화하여(tokenizing) semantic한 정보를 담아두기 위해 사용된다. (여기서 embedding vector가 되는 작업을 특정 단어를 임베딩화 한다 라고 볼 수 있다.)
word embedding은 trainable parameter를 가지고 있기 때문에 우리가 원하는 정보를 담도록 학습하는 것이 가능하다.
미리 학습시킨 단어들을 테이블에 매칭을 시켜서 훈련을 시키면 차원에 맞게 훈련이 된다.
기존의 DETR 계열의 decoder level에서 learnable objecy query라고 불리는 애들도 모두 위와 같은 embedding table을 두고 사용하는것이다.( 코드상으로 동일한 존재 Torch.nn.embedding() )
제안 방법론
Prompt engineering 자동화
- Prompt engineering : prompt의 context 단어들을 학습 가능한 벡터로 모델링
랜덤값 또는 pretrain된 word 임베딩으로 초기화
2가지 Implementation : unified context, class-specific context
- unified context : 모든 class에 동일한 context 공유
여기서 laernable context는 look up table을 이용해서 사용하며 고정된 값이다. class만 변경하여 사용한다.
[V]는 table값 하나하나를 의미한다. 총 M개의 vector가 생성된다.
Dimension은 512개(CLIP)
- class-specific context : 각 class에 대해서 context 토큰의 구체적인 set을 학습시킨 context
class가 변경될 때마다 learnable context의 값도 변경된다.
class별로 word embedding을 따로 만들어서 훈련하는 방법이다.

- Training :
학습방법은 CLIP과 동일
CLIP : 이미지, text 각각에 대해 학습된 두가지 임베딩 공간 align 하도록 학습시킴
learning objective : contrastive loss
- zero-shot inference:
CLIP :이미지가 text description과 매칭되는지를 예측하고자 함 ( zero - shot)
데이터로부터 end - to end로 learning, 대량 pre-train된 parameter들은 frozen

f : 이미지 x에 대해 인코더로 추출된 image feature
Wi : text encoder로 생성된 weight vector. "a photo of {class}" class 토큰은 구체적인 class 이름으로 대체 (dog, cat..)
K : 클래스 수
- Context optimization
manual prompt tuning 방지 : context 단어들을 continuous vector들로 모델링
데이터로부터 end - to - end로 learning, 대량 pre-train된 parameter들은 frozen
1. Unifeid Context
(클래스 토큰의 위치에 따라 2가지 경우존재)
- 모든 class에 동일한 context 공유


t : prompt
각각의 [V]는 word embedding과 동일한 D차원(CLIP의 경우 512)을 가지는 vector들을 의미하고
M은 context token수로 hyper-paramete로써 저자가 지정한 값이다.
단, 해당 값이 많아질수록 더 많은 semantic information을 담을 수 있지만 커질수록 훈련 parameter도 증가한다.
클래스가 끝에 위치한 경우는 word embedding에 class를 concat하여 사용한다.
클래스가 중간에 위치한 경우는 a photo of a {class},{description}과 같은 경우로 class가 중간에 오는 경우를 고려해 만든 방법이다.
2. Class-specific Context
- 각 class에 대해 특정 set의 context vector학습

Prediction

visual concept를 representation하는 classification weight vector획득 : g(t)
기존 prompt-learning 방법론들과의 차이점
- CLIP기반 모델과 language model의 backbone 구조 차이
| CoOP | languate model | |
| backbone 구조 | visual, text data를 모두 input으로 | text 데이터만 다룸 |
| pre- training objective | contrastive learning | autogressive learning |
실험결과
CLIP을 고정시킨채로 prompt만 변경하여 성능을 확인했다.
11개의 데이터셋에 대한 few-shot learning 결과
- CoOp은 CLIP을 강력한 few-shot learner로 바꿀 수 있음
M: context length
CSC : calss specific context


Linear probe CLIP은 few-shot SoTA.
1,2,4,8,16 image를 사용해서 훈련하고 성능을 측정하는 few-shot learning
여기서 CSC가 일반적으로 unified context방법에 비해 적은 성능을 보이는데, 이는 context word embedding이 적절이 훈련되지 못했을 것이라고 추측한다.
그러나, fine-grained dataset(flower)에서는 CSC가 더 좋은 성능을 보이기도 하였다.
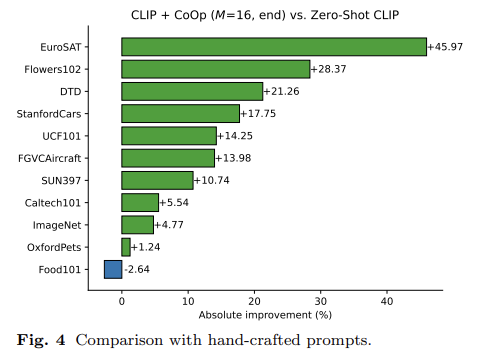
Hand crafted prompts와 비교시 대체적으로 좋은 성능을 보인다.
ablation, context length
word embedding [v]의 개수 M의 차이를 확인하는 ablation.
M이 커질수록 성능이 오른다.
그러나 개수가 늘어날수록 model performance를 위해 더 많은 훈련을 필요로 하며, overfitting될 가능성이 늘어나기 때문에 golden-rule은 없다.
context를 훈련하면 할수록 특정 dataset에 fitting되어 generality를 잃어버리기 때문이다. (trade-off)

Zero-shot performance를 위해서는 CLIP의 generality가 중요하기 때문에 훈련을 덜 해도 되는 M=4에서 좋은 성능을 보이고, few-shot에서는 이미지를 통해서 학습하고 성능을 측정하기 때문에 M=16이 제일 좋은 성능을 보인다.
따라서 zero-shot에서는 M이 커진다고 성능이 좋아지는것은 아니다.

Contribution
1. 기존 vision - language model의 문제점 : downstream task deployment 효율성 문제
2. continuous engineering 자동화
3. 기존 방법들보다 높은 성능 달성 : downstream transfer learning성능, robustness 측면에서 우수



